Incident Process
This document describes our incident handling process for network, operations and security issues.
This document assumes the user has a PagerDuty account and is part of the Modernisation Platform team. To use the in Slack features the user must authorise the PagerDuty app in Slack.
Overview:
For ease of use the key steps are documented within the overview, with further details in the sections below.
- Confirm that the event constitutes an incident:
If this incident constitutes a security breach, you must also contact the Service Desk to raise an incident.
- Declare the incident:
Create a PagerDuty incident (ensuring it is on the external status page) and a Slack channel. - Assign roles:
Incident Lead and Scribe are mandatory roles. - Managing the incident:
Including communication - and who to tell. - Fix the problem
Work towards resolving the incident. - Post-incident procedure
Complete follow-up actions, including documentation and review.
Detailed steps follow below:
1. Confirm that the event constitutes an incident
If this incident constitutes a security breach, you must also contact the Service Desk to raise an incident.
Service Desk Contact Information
| Method | Details |
|---|---|
| Phone (24/7) | 0800 917 5148 |
| Tech Portal Chat Bot | Technology Portal Homepage to contact a live agent |
Important: If the incident involves sensitive information or requires a password reset, this can only be done over the phone.
In most cases, contacting the Service Desk is sufficient. They will record the details of the incident and notify the Protective Monitoring Team to investigate. If additional information is required, they will reach out to us.
If the Service Desk recommends further action, such as emailing the JusticeDigitalSOC mailbox (justicedigitalsoc@justice.gov.uk) and/or the Security mailbox (security@justice.gov.uk), they will inform us. In such cases, we must include the INC reference number and provide a clear explanation for contacting the security teams.
For additional guidance, refer to the security incident reporting on the intranet.
We define an incident as an event which:
- is unplanned, and
- impacts end users or our direct users (developers and engineers), or
- degrades user-facing services, or
- increases risk to production services
If this event does not constitute an incident, the appropriate response is probably to raise an issue in our GitHub repository, however if the issue is security related, it is raised here.
Once you are confident that you have an incident, declare it as such.
2. Declare the incident
If an alarm has gone off it will already have created an incident, you can skip this step and use the incident already created in PagerDuty.
From the #modernisation-platform channel in Slack you can use the PagerDuty Slack app to declare an incident.
/pd trigger
Type
/pd helpto see other available PagerDuty commands, although most likely they will not be useful here.
Running /pd trigger will open the Declare Incident form in PagerDuty. Complete the fields as shown below:
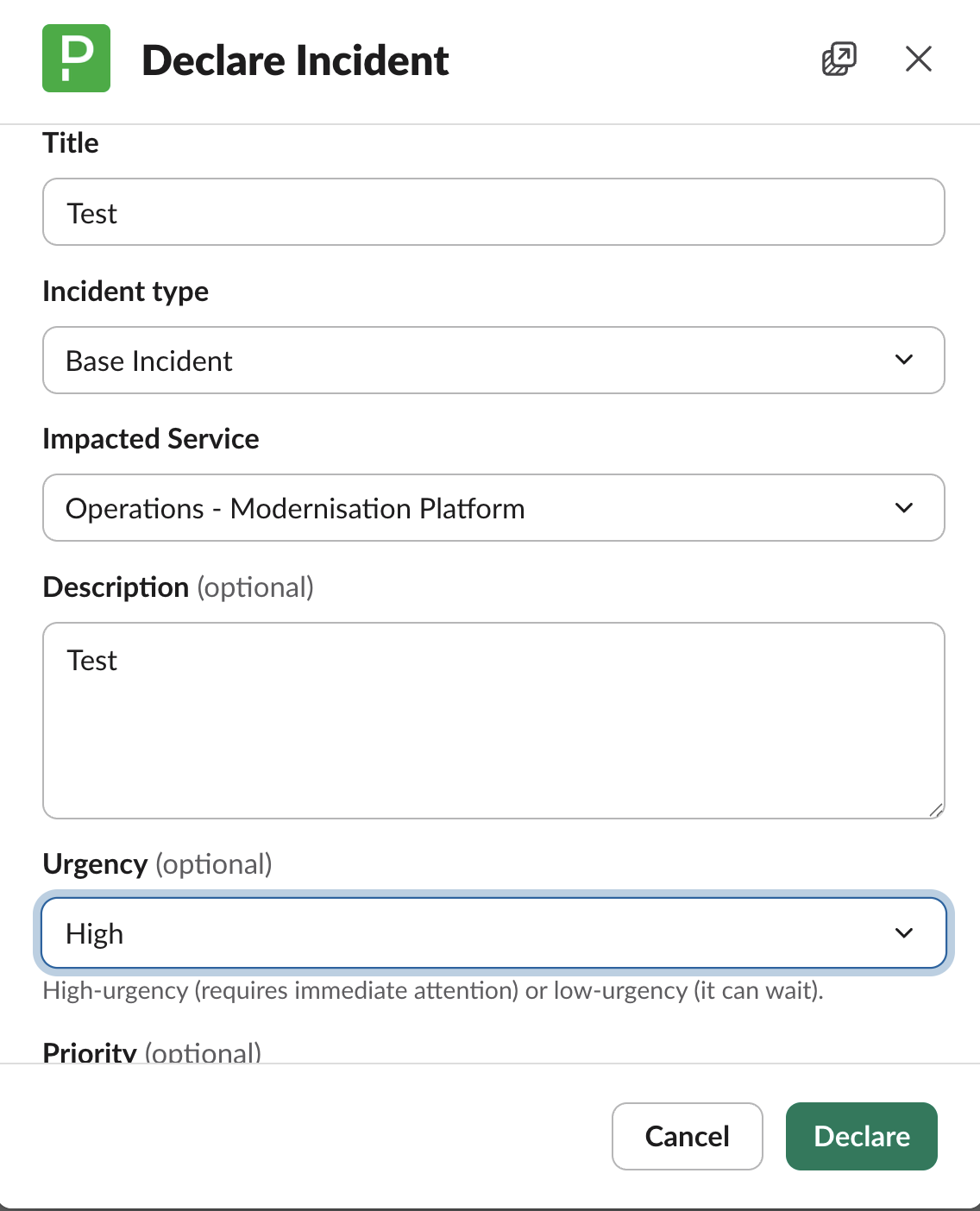
- Title – a short, clear description of the incident
- Incident type – select
Base Incident Impacted Service – choose from the following depending on the type of incident:
- Networking - Modernisation Platform
- Operations - Modernisation Platform
- Security - Modernisation Platform
Important: You must select one of the three services listed above. If you select any other service (e.g. a user or escalation policy from the dropdown), PagerDuty will not post to our
#high-priority-alertschannel, and the ask-modernisation-platform and modernisation-platform-update Slack channels will not be automatically notified via the Status Page integration.
The Impacted Service dropdown offers several options — ensure you select the correct one for your incident type, as shown below:
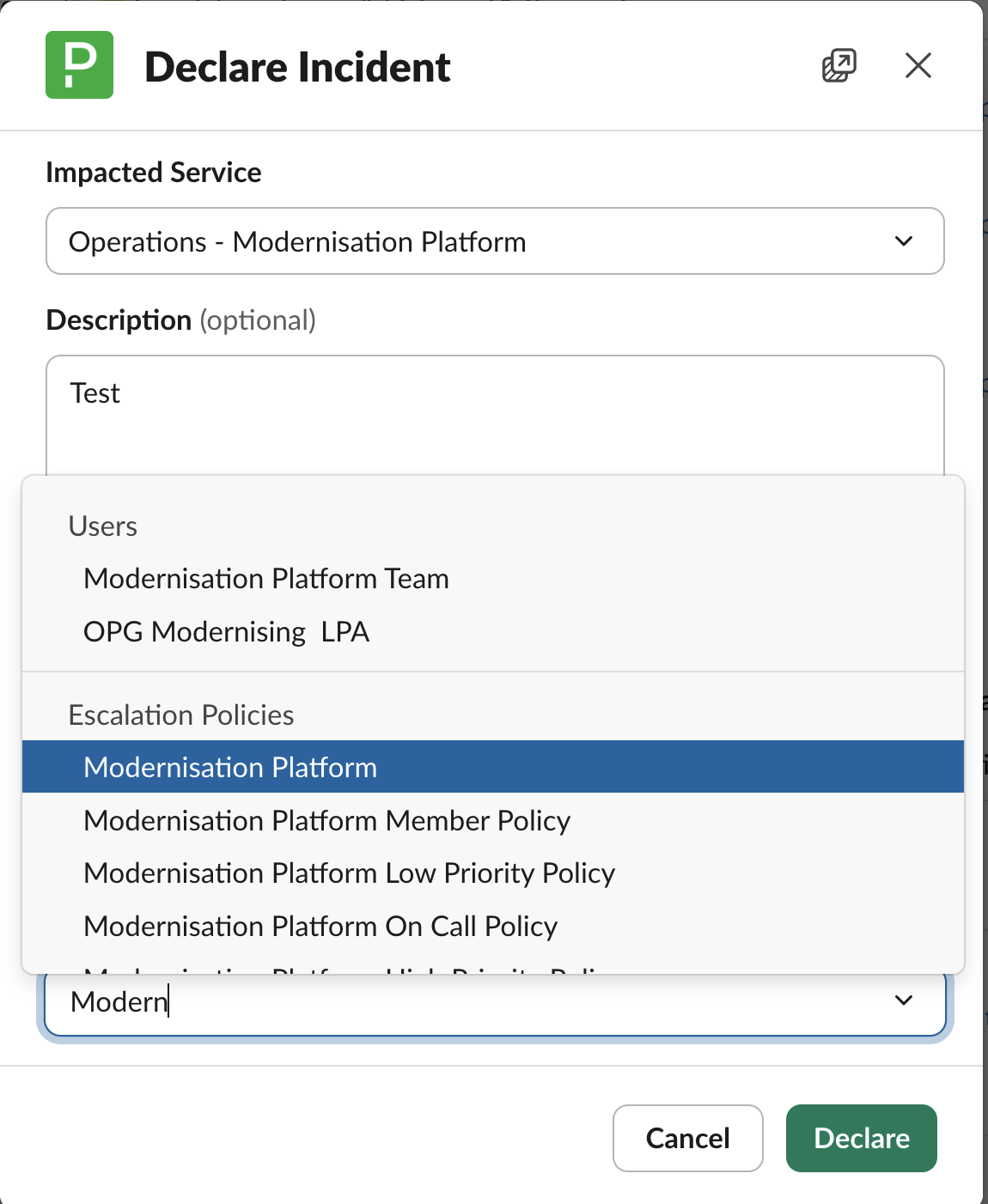
- Description – optional, but useful for context
- Urgency –
Highfor anything requiring immediate attention,Lowif it can wait - Priority – see the table below
Which Priority to assign?
We only use P1, P2 or P3
| Priority | Description |
|---|---|
| P1 | The whole platform is down or unavailable, all user applications are unavailable |
| P2 | Part of the platform is down or unavailable, some user applications are impacted or unavailable |
| P3 | Part of the platform is down or unavailable, user applications are still available |
Click Declare once you are happy with the form. This will create a new incident in PagerDuty and update the PagerDuty Status Page. The PagerDuty Status Page Slack integration will then automatically post a notification in the ask-modernisation-platform and modernisation-platform-update channels, as shown below:
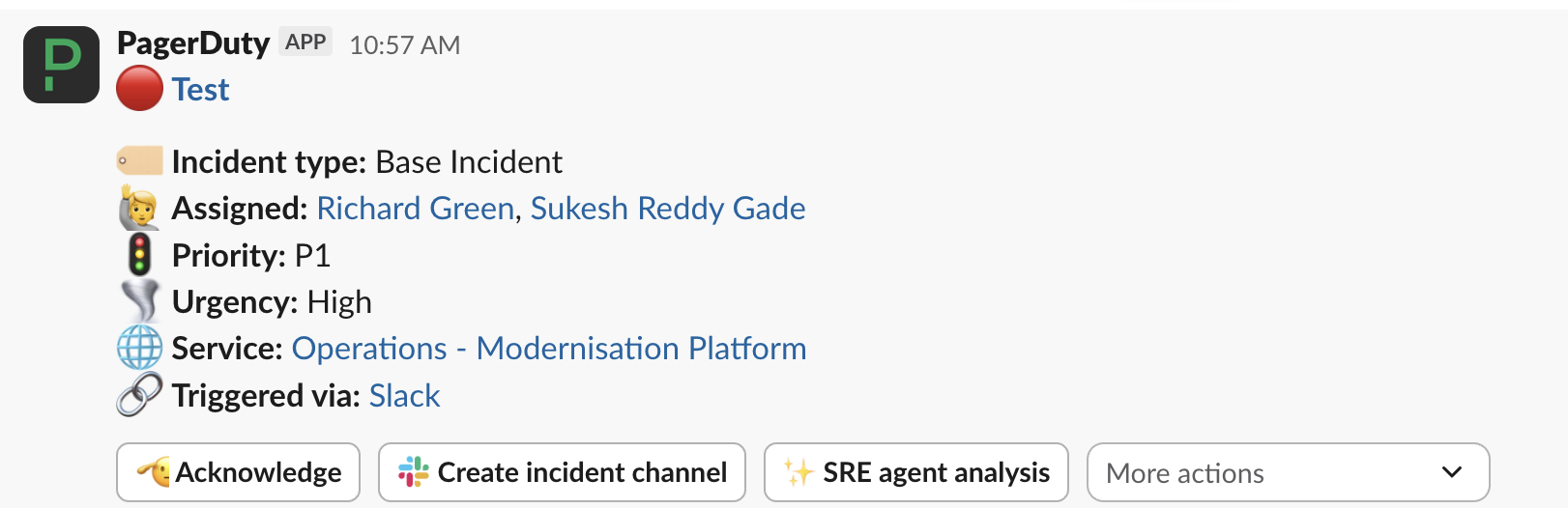
From the Slack notification you can Acknowledge the incident and use Create incident channel to set up a dedicated Slack channel for managing the incident.
At your discretion, you may also wish to notify users directly via ask-modernisation-platform and/or modernisation-platform-update, however please ensure that this does not replace the Status Page update (see later in the guidance).
3. Assign roles
The two roles which must be filled for every incident are the Incident Lead and the Scribe.
In rare cases, the same person might fill both roles, but this is discouraged because it generally leads to poor record keeping.
To fill these roles, ask for volunteers from the team, either verbally or via #modernisation-platform. In the unlikely event that you don’t get any volunteers, appoint someone.
3.1 Incident Lead
Responsibilities:
- coordinate our response to the incident
- decide on any additional roles required (e.g. a communications lead may be required)
- ensure that all required roles are filled
- if no communications lead required, the Incident Lead will be responsible for communicating
- ensure that all tasks which need to be handled are being done
- make the final decision whenever we need to choose a course of action
- set the schedule for any regular team check-ins, if those are deemed necessary
- declare the incident closed, when appropriate
- ensure that the post-incident process is followed
The incident lead needs to ensure that things are being done, not try to do everything themselves
3.2 Scribe
Anyone can make notes on the incident, but one person (and that could be the lead) should make sure the incident is documented.
Responsibilities:
The scribe is responsible for keeping a log of the incident, including:
- important events
- discussion topics
- decisions
- actions
- results of actions/investigations
This log is not intended to be a verbatim transcript of discussions. Rather, things like “xxx suggested the disk might be full. yyy to investigate and report back”
4. Managing the incident
4.1 Communicating
As well as communicating to our user base, the following people should be informed for a P1 or P2:
Head of Platforms and Architecture
Head of Hosting
Product Manager/Delivery Manager
4.2 Recording notes
Entries on the incident can be created from Slack using the Add a Note action option on the Incident Post in the incident dedicated slack channel (see below)
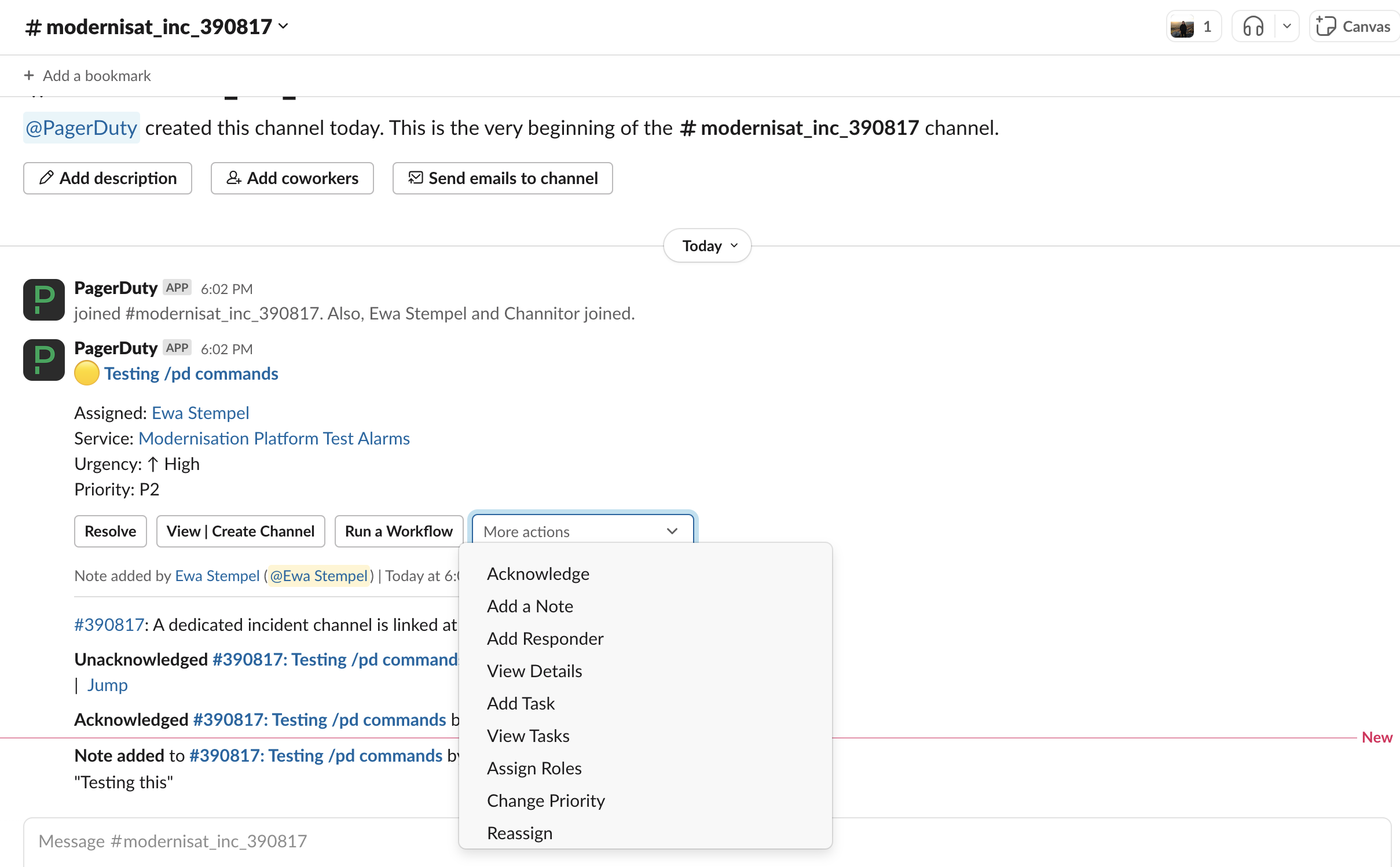
or via PagerDuty Incident page by clicking + Add Note button (see below)
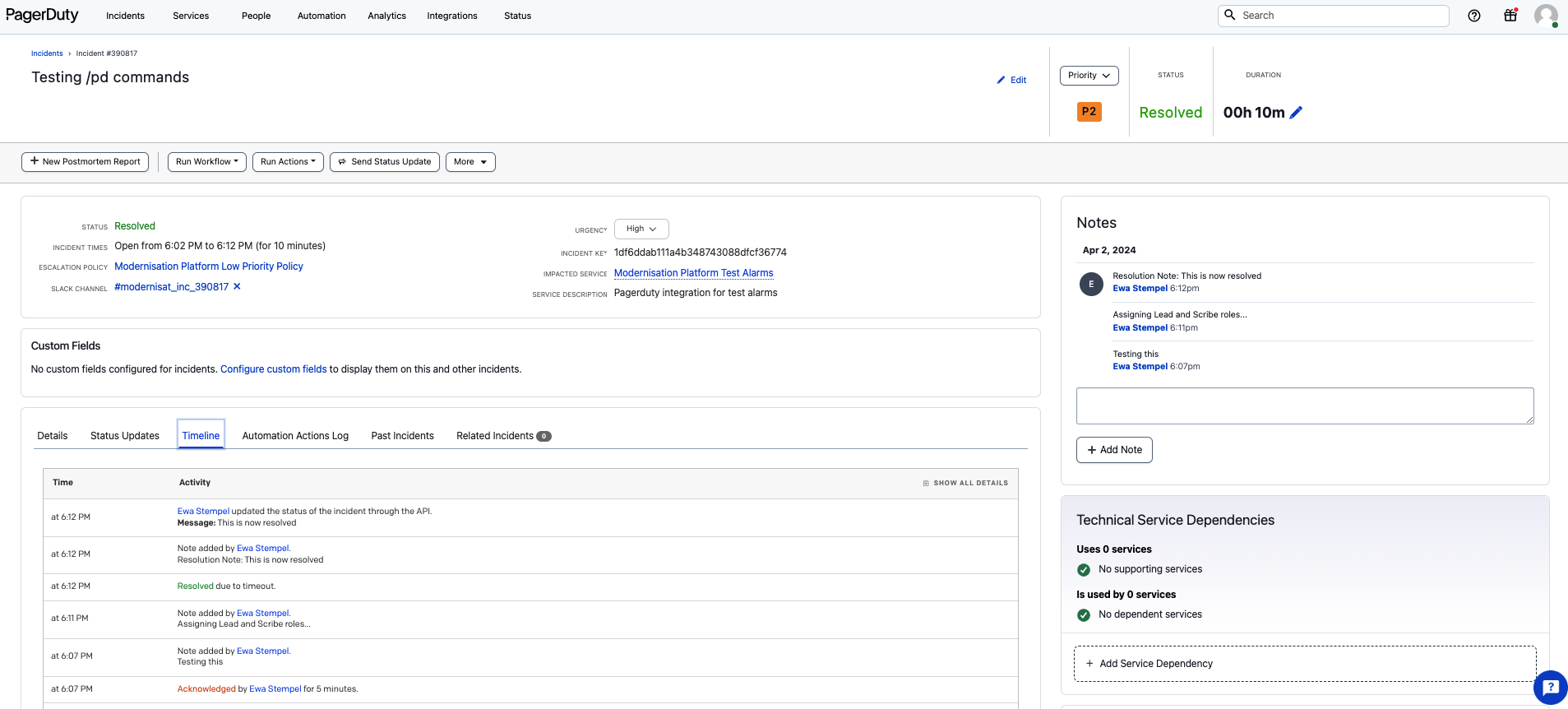
NOTE, other incident actions are also listed in the slack UI, e.g. Assign Roles, however not all of them are currently enabled (as some features cost extra). Therefore, managing these information may require a manual recording through Add a Note action instead.
Similarly, these features will not be available in the incident page.
4.3 Updating the External Status on PagerDuty
When an incident is raised, an update will become pending on the Modernisation Platform external status page (the internal status will be automatically updated).
An email will be sent to the Modernisation Platform team informing them of the pending update.
To publish the update to the external status page, click the link in the email or navigate to Status and External Status page in PagerDuty.
Fill in the details for the update and publish it, this will also post an update to the #ask-modernisation-platform and #modernisation-platform-update Slack channels.
It is important to use the External Status page as this feeds in to other services in PagerDuty dependant on the Modernisation Platform.
4.4 Transferring roles
It may be necessary to transfer roles from one team member to another, e.g. during long-running incidents. In this case, it is the responsibility of whoever is in a role to ensure that someone else takes it over.
Whoever assumes a role should announce it in the incident slack channel (or thread if the channel was not created), so that the team is aware.
5. Fix the problem
Please bear in mind that not every incident requires the whole team to be involved (even if they all want to join in).
Log a support ticket if necessary
If the incident cannot be resolved within the team or if the issue lies with a 3rd party log a support ticket with the 3rd party. For AWS support, log a call in the AWS account affected.
| 3rd Party | How to log a support ticket | Escalation process |
|---|---|---|
| AWS | Creating a support case | On the case, or post in #ext-aws |
6. End the incident
The incident is resolved once the user is no longer facing issues. This may be a temporary fix, in which case an issue should be created to put a permanent fix in place.
Resolve the incident via Slack or PagerDuty with a note on the resolution.
Update the external PagerDuty status page with the resolution.
This marks the official end of the incident.
6.1 Check the External Status Page for Pending Approvals
This step is easily missed — do not skip it.
Resolving an incident in PagerDuty automatically generates status page entries, but these are not published until they are manually approved. After resolving, navigate to the External Status Page in PagerDuty and check the Pending Approvals tab.
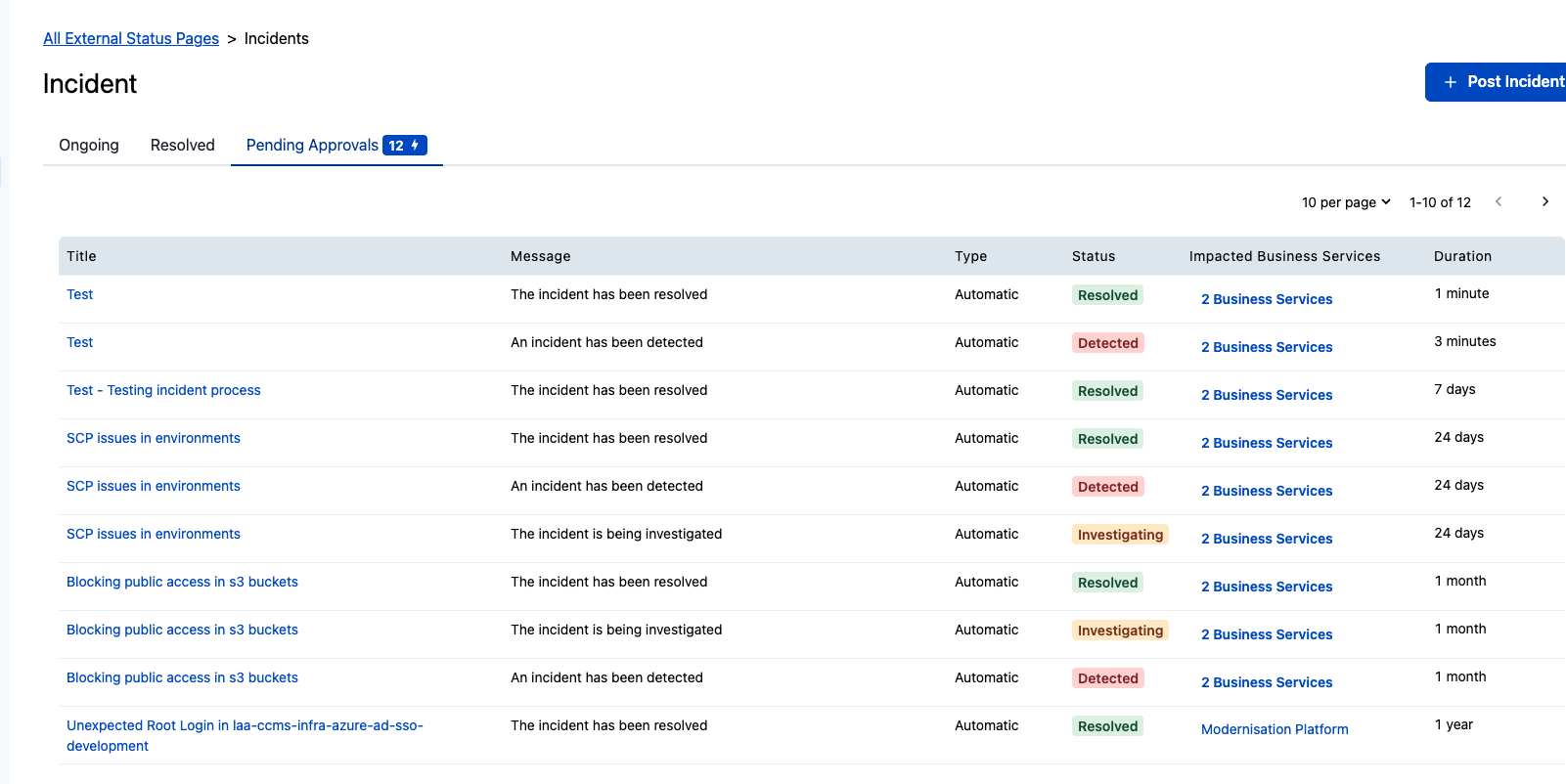
You may find multiple entries pending approval for the same incident (e.g. Detected, Investigating, and Resolved). Review and approve each one so that the public status page accurately reflects the full incident timeline.
Failing to approve these entries means the external status page will show no updates for the incident, which can cause confusion for users and dependant services.
7. Post-incident procedure
After the incident is resolved:
- A new incident report should be created and stored in the Modernisation Platform > Incidents drive directory. See an example of such report. The notes generated during the incident management in PagerDuty can be used for the incident timeline records.
- A blameless post mortem meeting should be scheduled to identify any processes that need to be improved
- A runbook for how to fix this issue should be published